- Category
- >Machine Learning
What is Random Forest Classifiers in Machine Learning?
- Bhumika Dutta
- Jan 31, 2022

Classifiers are used to aid machine learning. To figure out which observation belongs to which class, many types of classification algorithms are utilized. This is critical for a variety of commercial applications and consumer forecasts, such as determining if a certain user will purchase a product or predicting whether a given loan would fail.
Random forest algorithm is one such classifier used in machine learning that is used for both classification and regression problems. In this blog, we are going to learn the following:
-
Understanding Random Forest Classifiers
-
Classification in Random Forest
-
Working of Random Forest Classifiers
-
Advantages and Disadvantages of Random Forest Classifiers
-
Use cases of Random Forest Classifiers
Let us start the blog by understanding what Random Forest Classifiers are.
Random Forest Classifiers:
Random forest is a supervised learning technique for classification and regression algorithms in machine learning. It's a classifier that combines a number of decision trees on different subsets of a dataset and averages the results to increase the dataset's predicted accuracy.
It creates a "forest" out of an ensemble of decision trees, which are commonly trained using the "bagging" approach. The bagging method's basic premise is that combining several learning models improves the final output.
Instead of depending on a single decision tree, the random forest collects the forecasts from each tree and predicts the final output based on the majority votes of predictions.

A diagram to understand Random Forest Prediction (Source: JavaT point)
There are different features of the random forest classifiers, some of them are listed below:
-
It outperforms the decision tree algorithm in terms of accuracy.
-
It is a useful tool for dealing with missing data.
-
Without hyper-parameter adjustment, it can provide a fair forecast.
-
It overcomes the problem of decision tree overfitting.
-
At the node's splitting point in every random forest tree, a subset of characteristics is chosen at random.
(Must read: 5 Machine Learning Techniques to Solve Overfitting)
-
Decision Tree Algorithm:
Since it has been mentioned, it is necessary to understand the basics of the decision tree algorithm before moving forward. According to section.io, a random forest algorithm's building components are decision trees. A decision tree is a decision-making tool with a tree-like structure.
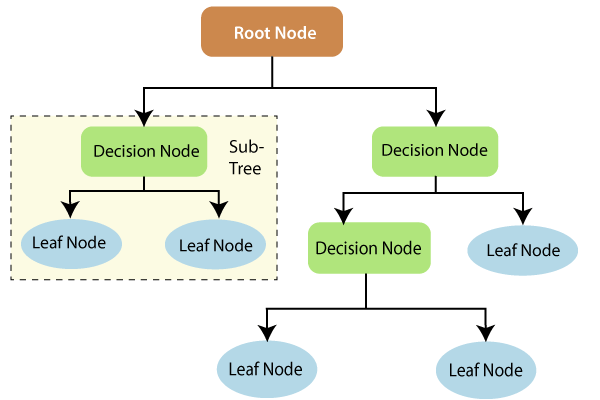
A basic understanding of decision trees will aid our understanding of random forest algorithms. There are three parts to a decision tree: decision nodes, leaf nodes, and root nodes. A decision tree method separates a training dataset into branches, each of which is further divided into branches. This pattern repeats until a leaf node is reached. There is no way to separate the leaf node any further.
The qualities utilized to forecast the result are represented by the nodes in the decision tree. The leaves are connected to the decision nodes. The three types of nodes in a decision tree are depicted in the diagram below.

Decision Tree (source: Tutorial and example)
-
Classification in Random Forest:
Random forest classification uses an ensemble technique to get the desired result. Various decision trees are trained using the training data. This dataset contains observations and characteristics that will be chosen at random when nodes are divided. Various decision trees are used in a rain forest system.
There are three types of nodes in a decision tree: decision nodes, leaf nodes, and root nodes.
Each tree's leaf node represents the ultimate result produced by that particular decision tree. The final product is chosen using a majority-voting procedure. In this situation, the ultimate output of the rain forest system is the output chosen by the majority of decision trees.
Working of Random Forest Classifiers:
We must first learn about the ensemble approach before we can comprehend how the random forest works. Ensemble simply refers to the process of merging numerous models. As a result, rather than using a single model to generate predictions, a collection of models is employed.
Ensemble approaches are divided into two categories:
-
Bagging– It produces a distinct training subset with replacement from sample training data, and the final output is based on a majority vote.
Take, for instance, Random Forest.
-
Boosting– It turns weak students into good students by generating sequential models with the maximum accuracy possible.
For instance, ADA BOOST and XG BOOST
The random forest method has the following steps:
Step 1: In a Random forest, n random records are chosen at random from a data collection of k records.
Step 2: For each sample, individual decision trees are built.
Step 3: Each decision tree produces a result.
Step 4: For classification and regression, the final output is based on Majority Voting or Averaging, accordingly.

{kind=link}
(Source: Analytics Vidhya)
-
Regression in random forests:
The other duty that a random forest algorithm does is regression. The principle of simple regression is followed by a random forest regression. In the random forest model, the values of dependent (features) and independent variables are transmitted. Random forest regressions may be performed in a variety of systems, including SAS, R, and Python.
Each tree in a random forest regression makes a unique prediction. The regression's result is the average forecast of the individual trees. This is in contrast to random forest classification, which determines the output based on the decision trees' class mode.
Although the concepts of random forest regression and linear regression are similar, their purposes differ. y=bx + c is the formula for linear regression, where y is the dependent variable, x is the independent variable, b is the estimated parameter, and c is a constant. A sophisticated random forest regression's function is similar to that of a black box.
(You can also read: What is Regression Analysis? )
Advantages and Disadvantages of Random Forest Classifier:
There are several advantages of Random Forest classifiers, let us learn about a few:
-
It may be used to solve problems involving classification and regression.
-
It eliminates overfitting because the result is based on a majority vote or average.
-
It works well even when there are null or missing values in the data.
-
Each decision tree formed is independent of the others, demonstrating the parallelization characteristic.
-
Because the average answers from a vast number of trees are used, it is extremely stable.
-
It preserves diversity since all traits are not taken into account while creating each decision tree, albeit this is not always the case.
-
It is unaffected by the dimensionality curse. The feature space is minimized since each tree does not evaluate all of the properties.
-
We don't need to separate data into train and test since there will always be 30% of the data that the bootstrap decision tree will miss.
But, like advantages, there are a few disadvantages of this algorithm as well. Some of them are:
-
When employing a random forest, additional computing resources are required.
-
When compared to a decision tree algorithm, it takes longer.
Use cases of Random Forest classifier algorithm:
-
Banking
In banking, a random forest is used to estimate a loan applicant's creditworthiness. This assists the lending organization in making an informed judgment about whether or not to grant the loan to the consumer. The random forest technique is often used by banks to detect fraudsters.
-
Health-care services
Random forest algorithms are used by doctors to diagnose patients. Patients are diagnosed by looking at their past medical records. Previous medical data are examined to determine the proper dose for the patients.
-
The stock exchange
It is used by financial experts to discover prospective stock markets. It also helps them to recognize the stock activity.
-
E-commerce
E-commerce platforms may forecast client preferences based on prior consumption behaviour using rain forest algorithms.
Conclusion
One of the nicest aspects of random forest is that it can accept missing variables, so it's a perfect choice for anyone who wants to create a model quickly and effectively.
This approach is useful for developers since it eliminates the problem of dataset overfitting. It's a highly useful tool for creating accurate predictions in businesses' strategic decision-making.
We can now conclude that Random Forest is one of the greatest high-performance strategies that is extensively employed in numerous sectors due to its efficacy. It can handle data that is binary, continuous, or categorical. Random forest is a quick, simple, versatile, and durable model, but it does have certain drawbacks.
Share Blog :
Or
Be a part of our Instagram community
Trending blogs
5 Factors Influencing Consumer Behavior
READ MOREElasticity of Demand and its Types
READ MOREAn Overview of Descriptive Analysis
READ MOREWhat is PESTLE Analysis? Everything you need to know about it
READ MOREWhat is Managerial Economics? Definition, Types, Nature, Principles, and Scope
READ MORE5 Factors Affecting the Price Elasticity of Demand (PED)
READ MORE6 Major Branches of Artificial Intelligence (AI)
READ MOREScope of Managerial Economics
READ MOREDifferent Types of Research Methods
READ MOREDijkstra’s Algorithm: The Shortest Path Algorithm
READ MORE
Latest Comments